데이터가 많은 경우, 트래픽이 문제되는 경우 샤딩 기법을 사용해서 더 적은 데이터 셋, 트래픽 분산을 처리할 수 있다.
이전에는 애플리케이션 레벨에서 직접 DataSource 커스텀, ShardingSphere - jdbc를 사용해서 샤딩을 구현해보았다.
하지만 RDBMS에서 샤딩을 구성했고 현재 momo 프로젝트에서는 채팅 메시지 저장 목적으로 MongoDB를 사용하기에 MongoDB에서 샤딩을 어떻게 적용하는지 궁금해졌다.
따라서 샤딩을 MongoDB의 샤딩 방법을 공부하고 프로젝트에 적용해 볼 예정이다.
1. DB 레벨에서의 샤딩
MongoDB는 DB 레벨에서의 샤딩을 지원해준다.
이전 애플리케이션 레벨에서는 서버측에서 라우팅 처리를 해서 디비에 직접 연결했다. 즉, 추상화가 덜 되었다고 말할 수 있다. 하지만 MongoDB는 DB 자체에서 샤딩을 사용할 수 있게 해준다. 이는 RDBMS에서 파티셔닝을 지원해준 것처럼 개발자는 논리적인 테이블에 접근하고, 실제로는 파티션 단위로 저장되는 구조를 생각하면 된다. 이렇게 역할을 분리함으로써 개발자는 개발에 더 집중할 수 있고 DBA는 디비에 더 집중할 수 있다.
그렇다면 MongoDB가 어떻게 DB 레벨에서 샤딩을 지원해줄까?
2. MongoDB Sharded Cluster

MongoDB는 샤딩 클러스터 환경을 제공한다.
mongos라는 라우터, 샤드들의 메타데이터를 제공하는 config server, 실제 shard로 구성된다.
이제 새로운 단어들에 대해서 알아보자.
[ mongos ]
mongos는 라우팅 기능을 제공하는 mongodb 서버이다.
서버에서 온 요청이 어떤 샤드로 가야하는지에 대한 길잡이 역할을 한다.
[ config server ]
config server는 샤드가 어떤 메타데이터를 가지는지를 가진 설정 정보 저장 서버이다.
mongos는 config server에서 샤드 키에 매칭되는 정보를 찾아서 적절한 shard로 요청을 분배한다.
mongodb 3.4버전부터 shard cluster 환경을 구성할 때에는 config server를 replica set으로 구성해야한다.
[ shard ]
데이터가 저장되는 디비 서버를 의미한다.
mongos가 적절한 샤드를 선택해서 데이터를 주고받는다.
****** 왜 mongos에는 "1 or more router"라고 적었는데 replica set이라고 명시를 하지 않았을까?
mongos도 여러개로 유지해야 한다는 의미인거 같은데 왜 replica set이라고 명시를 안하고 다른 곳은 명시를 했지? 라는 의문이 생겼다.
답은 mongos의 stateless한 환경에 있다.
replica set을 구축하는 이유는 데이터의 안정성을 위한 것이다. 즉, heartbeat나 ping/pong을 통해 데이터를 secondary에 백업해놓고 자동 failover를 지원하기 위함이다.
하지만 mongos는 요청을 routing하는 역할만 한다. 즉, mongos1과 mongos2의 데이터 동기화가 필요하지 않기 때문에 서로 연결될 필요가 없다는 것이다.
또한 백엔드 서버는 mongos와 직접적으로 연결되어있다. 즉, mongos1과 mongos2 모두에 연결되어 있다는 뜻이다. mongos1이 다운되더라도 Spring Boot MongoDB 드라이버가 이를 감지하고 mongos2로 재요청한다.
따라서 mongos는 replica set으로 구축할 필요가 없다.

위 그림은 대략적인 MongoDB Sharded Cluster 구성도이다.
이러한 구조로 구성되어 개발자는 mongos에 데이터를 요청하면 되기 때문에 비즈니스 로직에 더 집중할 수 있다.
3. 실습
깃허브 주소: https://github.com/Hellin22/hellin22-test-repo/tree/main/sharding-nosql
버전:
- Spring Boot: 3.5.6
- MongoDB: mongo:7 image
구성: Application Server 1대, mongos 2대, config server 3대(Replica Set), shard 9대(3대씩 Replica Set)
1. docker compose
services:
# ===== Config Server Replica Set (3대) =====
config1:
image: mongo:7
container_name: mongo-config1
command: mongod --configsvr --replSet configRS --port 27019
# --configsvr = Config Server용
# --replSet configRS = 레플리카셋의 이름 지정(configRS)
ports:
- "27019:27019"
volumes:
- config1:/data/db
networks:
- mongo-network
config2:
image: mongo:7
container_name: mongo-config2
command: mongod --configsvr --replSet configRS --port 27019
ports:
- "27020:27019"
volumes:
- config2:/data/db
networks:
- mongo-network
config3:
image: mongo:7
container_name: mongo-config3
command: mongod --configsvr --replSet configRS --port 27019
ports:
- "27021:27019"
volumes:
- config3:/data/db
networks:
- mongo-network
# ===== Shard 1 Replica Set (3대) =====
shard1-1:
image: mongo:7
container_name: mongo-shard1-1
command: mongod --shardsvr --replSet shard1RS --port 27018
# --shardsvr = shard Server용
ports:
- "27031:27018"
volumes:
- shard1-1:/data/db
networks:
- mongo-network
shard1-2:
image: mongo:7
container_name: mongo-shard1-2
command: mongod --shardsvr --replSet shard1RS --port 27018
ports:
- "27032:27018"
volumes:
- shard1-2:/data/db
networks:
- mongo-network
shard1-3:
image: mongo:7
container_name: mongo-shard1-3
command: mongod --shardsvr --replSet shard1RS --port 27018
ports:
- "27033:27018"
volumes:
- shard1-3:/data/db
networks:
- mongo-network
# ===== Shard 2 Replica Set (3대) =====
shard2-1:
image: mongo:7
container_name: mongo-shard2-1
command: mongod --shardsvr --replSet shard2RS --port 27018
ports:
- "27041:27018"
volumes:
- shard2-1:/data/db
networks:
- mongo-network
shard2-2:
image: mongo:7
container_name: mongo-shard2-2
command: mongod --shardsvr --replSet shard2RS --port 27018
ports:
- "27042:27018"
volumes:
- shard2-2:/data/db
networks:
- mongo-network
shard2-3:
image: mongo:7
container_name: mongo-shard2-3
command: mongod --shardsvr --replSet shard2RS --port 27018
ports:
- "27043:27018"
volumes:
- shard2-3:/data/db
networks:
- mongo-network
# ===== Shard 3 Replica Set (3대) =====
shard3-1:
image: mongo:7
container_name: mongo-shard3-1
command: mongod --shardsvr --replSet shard3RS --port 27018
ports:
- "27051:27018"
volumes:
- shard3-1:/data/db
networks:
- mongo-network
shard3-2:
image: mongo:7
container_name: mongo-shard3-2
command: mongod --shardsvr --replSet shard3RS --port 27018
ports:
- "27052:27018"
volumes:
- shard3-2:/data/db
networks:
- mongo-network
shard3-3:
image: mongo:7
container_name: mongo-shard3-3
command: mongod --shardsvr --replSet shard3RS --port 27018
ports:
- "27053:27018"
volumes:
- shard3-3:/data/db
networks:
- mongo-network
# ===== Mongos Router (2대) =====
mongos1:
image: mongo:7
container_name: mongo-mongos1
command: mongos --configdb configRS/config1:27019,config2:27019,config3:27019 --bind_ip_all --port 27017
# config server 위치 지정
ports:
- "27017:27017"
depends_on:
- config1
- config2
- config3
networks:
- mongo-network
mongos2:
image: mongo:7
container_name: mongo-mongos2
command: mongos --configdb configRS/config1:27019,config2:27019,config3:27019 --bind_ip_all --port 27017
ports:
- "27018:27017"
depends_on:
- config1
- config2
- config3
networks:
- mongo-network
volumes:
config1:
config2:
config3:
shard1-1:
shard1-2:
shard1-3:
shard2-1:
shard2-2:
shard2-3:
shard3-1:
shard3-2:
shard3-3:
networks:
mongo-network:
driver: bridge
2. Config Server Replica Set 설정
샤드의 메타데이터 정보를 저장할 Config Server 3개를 연결해 Replica Set으로 구성한다.
docker exec -it mongo-config1 mongosh --port 27019
rs.initiate({
_id: "configRS",
members: [
{ _id: 0, host: "config1:27019" },
{ _id: 1, host: "config2:27019" },
{ _id: 2, host: "config3:27019" }
]
})Replica Set 설정을 하고 나면 { ok: 1 }이 뜨고 프롬프트에 direct: secondary나 direct: primary로 뜰 것이다.

이후 rs.status() 명령어로 레플리카셋을 확인해보면

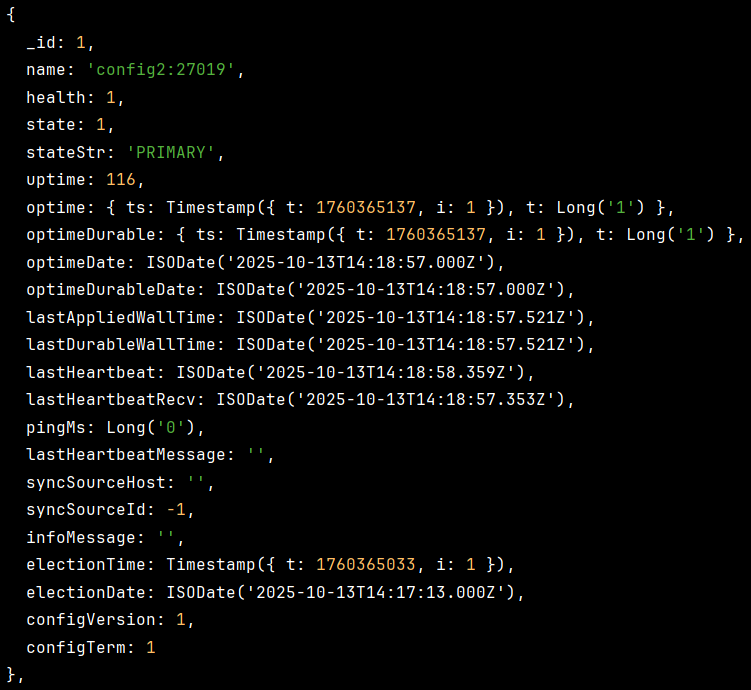
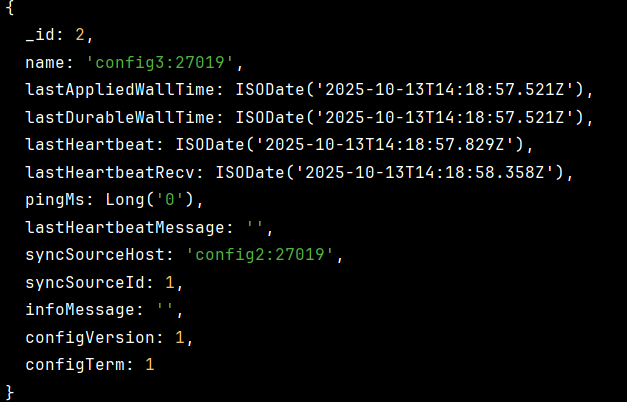
이렇게 Replica Set이 잘 설정된걸 볼 수 있다.
** 주의할점
docker-compose.yml의 config server에 설정한 이 부분
docker-compose.yml
config1:
...
command: mongod --configsvr --replSet configRS --port 27019
...
rs.initiate({
_id: "configRS",
...
})저기서 --replSet 다음에 나오는 명칭과 rs.initiate의 _id:의 명칭이 같아야한다.
3. Shard Server Replica Set 설정
우리는 총 3개의 샤드로 구성하고 각 샤드는 모두 3개의 Replica Set으로 구성된다.
따라서 3개의 환경을 구성해준다.
## 1. Shard 1 레플리카셋 구성
docker exec -it mongo-shard1-1 mongosh --port 27018
rs.initiate({
_id: "shard1RS",
members: [
{ _id: 0, host: "shard1-1:27018" },
{ _id: 1, host: "shard1-2:27018" },
{ _id: 2, host: "shard1-3:27018" }
]
})
## 2. Shard 2 레플리카셋 구성
docker exec -it mongo-shard2-1 mongosh --port 27018
rs.initiate({
_id: "shard2RS",
members: [
{ _id: 0, host: "shard2-1:27018" },
{ _id: 1, host: "shard2-2:27018" },
{ _id: 2, host: "shard2-3:27018" }
]
})
## 3. Shard 3 레플리카셋 구성
docker exec -it mongo-shard3-1 mongosh --port 27018
rs.initiate({
_id: "shard3RS",
members: [
{ _id: 0, host: "shard3-1:27018" },
{ _id: 1, host: "shard3-2:27018" },
{ _id: 2, host: "shard3-3:27018" }
]
})Config Server를 구성할 때와 같은 결과가 나오면 성공이다.
4. Mongos에 Shard(Replica Set) 정보 추가
4번을 진행하면서 궁금증이 생겼다.
샤드에 대한 메타데이터는 Config Server에 저장되는데, 왜 mongos에 접속해서 샤드 정보를 설정해야 하는가?
이는 mongos가 샤드에 접근하고 검증할 수 있기 때문이다.
샤드 추가시 필요한 작업은 다음과 같다.
1. 샤드 연결 테스트
2. 각 샤드 Replica Set 검증
3. Config Server에 메타데이터 저장
4. 초기 청크 할당
5. mongos 캐시 갱신
Config Server에서 처리하면 샤드에 접근이 불가능하기 때문에 위 과정을 수행하지 못한다.
따라서 mongos에서 주어진 정보를 통해서 샤드에 연결할 수 있는지를 확인하고 Config Server에 저장한다.
docker exec -it mongo-mongos1 mongosh --port 27017
# mongos와 shard 연결
sh.addShard("shard1RS/shard1-1:27018,shard1-2:27018,shard1-3:27018")
sh.addShard("shard2RS/shard2-1:27018,shard2-2:27018,shard2-3:27018")
sh.addShard("shard3RS/shard3-1:27018,shard3-2:27018,shard3-3:27018")
# 설정된 샤드 정보 확인
sh.status()
mongos 중 한곳에 접속해서 shard 정보를 추가한다.
mongos는 라우터 기능을 하고 결국 정보는 config server에 저장하기 때문에 아무 곳에서나 해도 상관없다.

샤드1을 샤드로 등록했고 2, 3에 대해서도 똑같이 등록한다.

모두 등록하고 sh.status()를 하면 위와 같은 샤딩 결과를 볼 수 있다.
spring:
data:
mongodb:
uri: mongodb://localhost:27017,localhost:27018/chatdb이제부터 애플리케이션 서버는 db와 직접 연결하는게 아닌 mongos에 연결해서 db와 상호작용 할 수 있다.
5. mongos 샤드키 설정
0. 샤드키 인덱스 생성 (필수 선행 조건)

- MongoDB는 샤드 키에 대한 인덱스를 필수로 요구한다.
- 샤드를 진행할 컬렉션이 비어있는 경우 샤드 키를 인덱스로 모든 샤드에 생성한다.
- 만약 컬렉션이 비어있지 않다면 따로 인덱스를 생성해주고 샤드 키를 지정해야한다.



mongos에서 use chatdb 후에 chat_message의 chat_room_id에 인덱스를 생성한다.
mongos는 라우팅만 처리하는 노드이고 mongos에서 use chatdb를 할 때 실제로 존재하는 프라이머리 샤드로 라우팅한다.
이후에 인덱스를 생성하면 샤딩된 모든 샤드에 인덱스를 생성해준다.
물론 각 샤드에 들어가서 use chatdb와 createIndex를 생성해도 된다. 하지만 mongos를 사용하면 한번으로 설정 가능하다.
use chatdb
db.chat_message.createIndex({ chat_room_id: "hashed" })
1. mongos 접속
docker exec -it mongo-mongos1 mongosh --port 27017
2. 샤딩을 사용할 데이터베이스 지정
sh.enableSharding("chatdb")
3. 샤딩에 사용할 샤드키 설정
sh.shardCollection("chatdb.chat_message", {chat_room_id: "hashed"})
4. sh.status()로 샤딩 설정 확인
sh.status()

현재 shard3RS에 28개의 데이터가 저장되어 있다고 나와있다.
*** 주의할 점: MongoDB의 hashed
샤드를 처리하는 방법 중에 많이 사용되는 방식이 Range 방식과 Hash 방식이 있다고 알고 있다.
이때, 대부분 hash 방식은 modular 방식을 사용한다고 알고있다.
따라서 mongodb에서 hash를 사용하면 chat_room_id에 대해서 % 연산으로 분산 저장한다고 생각했다.
하지만 hashed로 했을 때 chat_room_id가 다른데도 모두 샤드 3에 저장되는 문제가 있었다.
sh.status()를 해서 보면 28개의 데이터가 모두 샤드3번으로 들어간걸 알 수 있다.

오해: hashed를 사용하면 chat_room_id의 해시값(% 기반)으로 균등하게 분배.
실제: hashed를 사용하면 mongodb 내부 해시함수(SHA-1 기반)을 통해 분배.
여기서 의문이 들었다.
결국 현재도 균등하게 분배가 되지 않은 상황이다. (샤드1, 2는 데이터 0개, 샤드3은 데이터 28개)
또한 사용할 해시함수가 동적으로 바뀌지 않는다.(동일한 값은 동일한 해시값을 리턴해야하기 때문)
즉, 현재 데이터의 chat_room_id는 1, 2, 3 중 하나이고 hashed(1)의 값이 나중에 바뀌지 않기 때문에 이후에도 샤드3에 들어간다.
그렇다면 chat_room_id가 1, 2, 3인 데이터는 항상 샤드3에 저장될텐데 어떻게 균등 분배를 처리해주는가?가 궁금했다.
결론적으로 말하면 청크단위로 데이터를 다른 샤드로 마이그레이션하면서 균등한 데이터 분포를 이루게 해준다.
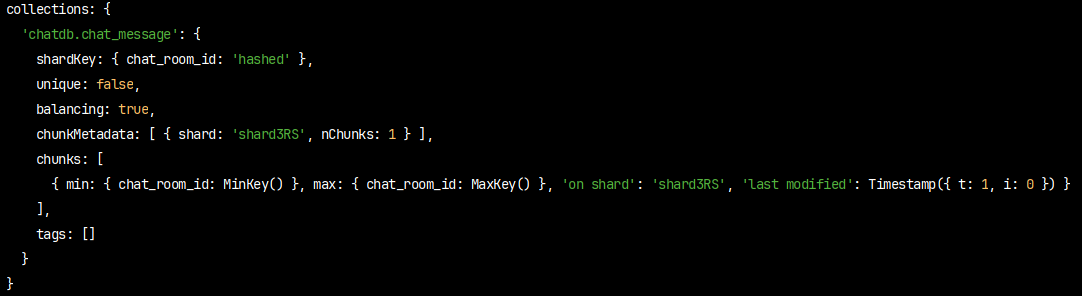
sh.status()를 쓰면 나오는 부분 중 하나인데 chunks에 min, max와 shard3RS가 적혀있다.
즉 현재는 샤드3에 -∞ ~ ∞ 의 해시 값이 들어있다는 뜻이다.
이 청크는 크기 제한이 있고 크기가 제한을 넘어서면 청크를 분할해서 다른 샤드로 옮긴다.

MongoDB의 기본 청크 크기는 128MB이다. 따라서 샤드3에 있는 청크가 128MB보다 커진다면 샤드1이나 샤드2로 데이터를 이관하는 작업이 발생한다.
이 과정을 테스트해보기 위해서 청크 크기를 1MB로 낮춰서 진행해보았다.
docker exec -it mongo-mongos1 mongosh --port 27017
use config
db.settings.updateOne(
{ _id: "chunksize" },
{ $set: { _id: "chunksize", value: 1 } },
{ upsert: true }
)
db.settings.findOne({ _id: "chunksize" })
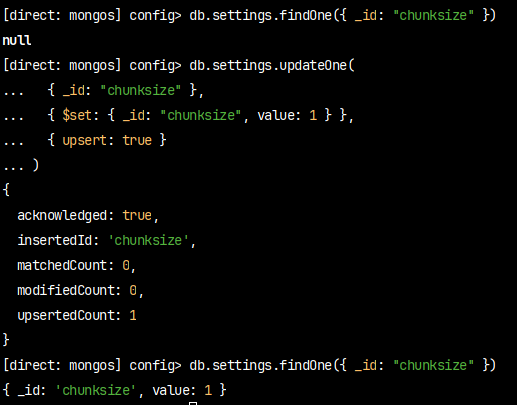
chunksize가 1로 바뀐걸 확인 수 있다.
이제 다시 chatdb로 가서 데이터를 추가해보자.
use chatdb
// 5000개 추가 (1MB 도달용)
for(let i=1; i<=5000; i++) {
db.chat_message.insertOne({
chat_room_id: i,
message: "테스트 메시지입니다. 데이터 크기를 늘리기 위한 긴 문자열입니다. 청크 분할 테스트를 위한 데이터입니다. ".repeat(5)
})
}데이터를 추가할때 시간이 좀 걸린다.

데이터 입력한 후에 sh.status()로 살펴보면
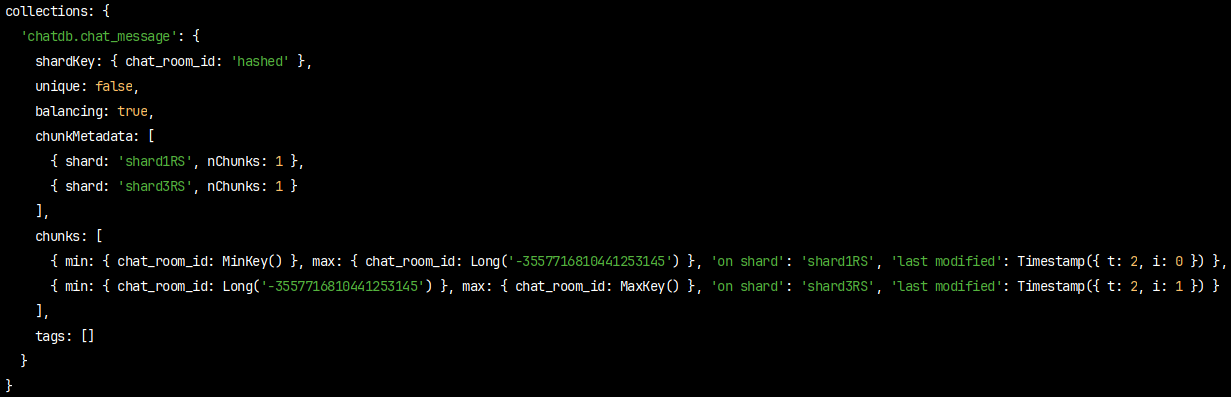
샤드3에만 있던 데이터가 샤드1에도 있는걸 확인할 수 있다.
또한 min, max 값이 -∞ ~ ∞ 가 아닌 명확하게 구분되어 저장되는걸 확인할 수 있다.
*** 궁금한점: 데이터 마이그레이션 작업 중 쿼리가 발생한다면?
모든 분야에서 고려해야할 점인 마이그레이션 작업 처리 중에 요청이 들어오면 일관성을 유지할 수 있는가가 궁금했다.
결론적으로는 문제가 발생하지는 않는다.
샤드3에서 샤드1로 마이그레이션을 시작할 때 샤드3의 청크 데이터 스냅샷을 찍고 스냅샷에 있는 데이터를 복사한다.
이때 config server에 마이그레이션을 하고있다는 정보를 적어놓는다.
마이그레이션 도중에는 계속해서 샤드3에 데이터를 저장하고 조회한다. 계속해서 추가되는 데이터의 변경사항은 oplog(binary 데이터)를 통해서 추적한다. 한번 마이그레이션이 끝난 후 oplog의 차이만큼 변경된 데이터를 샤드1로 추가로 복사한다.
모두 복사했다면 샤드3에 쓰기 차단을 걸고 변경사항 동기화 및 config server의 메타데이터를 업데이트한다.(샤드3 -> 샤드1으로의 마이그레이션 종료, hash 청크 정보 업데이트 == 샤드1에 데이터 저장)
이후 샤드3에서 이관된 데이터를 모두 제거한다.
마이그레이션 작업은 백그라운드로 돌기 때문에 다른 쿼리 작업도 동시에 수행 가능하다.
하지만 공식문서에서도 확인할 수 있듯이 빈번하고 잠재적으로 잘못된 마이그레이션을 피하는 것이 바람직하다.
마이그레이션 작업 자체는 동기화 문제가 있을 수 있고 cost가 큰 작업이기 때문에 자주 발생하면 좋지않다. 최대한 안일어나도록 서비스의 데이터양에 따라 chunk size를 적절하게 설정해야 한다.
결론
MongoDB의 샤딩을 구현해보았다. 생각보다 application 레벨에서는 처리할게 없어서 놀랐다.
momo 프로젝트에도 그대로 적용해서 대용량 채팅 데이터, 대규모 트래픽 처리에 유연한 서비스로 업그레이드 해보자.
출처
1. https://docs.spring.io/spring-data/mongodb/reference/mongodb/sharding.html
2. https://www.promleeblog.com/blog/post/263-9-mongodb-shading
3. https://www.mongodb.com/ko-kr/docs/manual/core/sharding-data-partitioning/#chunk-size
5. https://oliveyoung.tech/2024-12-17/catalog-mongo-transaction-2/
'일기' 카테고리의 다른 글
| [개발일기] Real MySQL 1권 (0) | 2025.10.23 |
|---|---|
| [개발일기] JWT와 Session에 대한 생각 (2) | 2025.10.15 |
| [개발일기] - 파티셔닝과 샤딩 (1) | 2025.10.05 |
| [개발일기] - 인덱스에 대해서 자세히 알아보기 (0) | 2025.10.01 |
| [개발일기] 09.19 - 데이터베이스란 무엇인가? (0) | 2025.09.19 |