주제
파티셔닝과 샤딩이 어떻게 동작하는지 파악하기
동기
데이터베이스는 인덱스를 통해서 데이터를 빠르게 가져올 수 있다. 하지만 인덱스라고 해서 만능은 아니라고 생각한다.
인덱스 자료구조를 유지하기 위해 계속 정렬을 해야하는 단점이 있고 절대적인 데이터의 양이 많아진다면 인덱스를 활용한다고 해도 성능이 안좋아지게 된다.
이를 위한 기술로 파티셔닝과 샤딩이라는 기술이 존재한다고 알고있다. 이론적으로만 알고 있을 뿐 실제로 어떻게 동작하는지 궁금해서 찾아보기로 했다.
알게 된 내용
1. 파티셔닝
[ 파티셔닝 ]
파티셔닝은 하나의 논리적 테이블을 물리적으로 여러 조각으로 분할해서 저장하는 것을 의미한다.
하나의 DB 서버에서 하나의 테이블을 여러 파티션에 나눠서 저장하는 것이고 수평적 파티셔닝과 수직적 파티셔닝이 존재한다.
[ 수직적 파티셔닝 ]
수직적 파티셔닝은 테이블을 col 기준으로 나눠서 서로 다른 테이블에 저장하는 것이다.
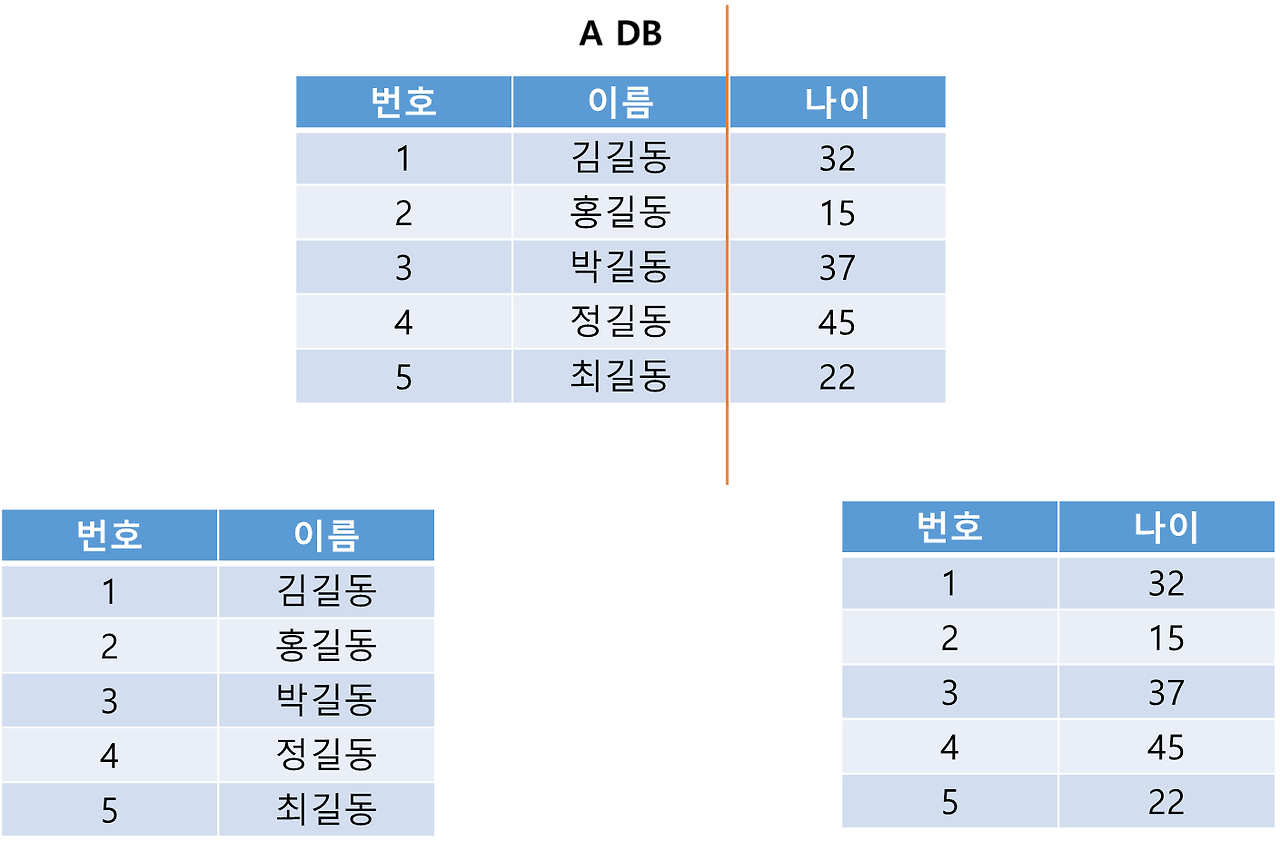
수직적 파티셔닝의 경우에 정규화를 통해서 데이터를 분리하는 것과 비슷한 개념이다.
하지만 정규화를 통해 외래키로 참조하게 테이블을 분리하는게 아니라 동일한 pk를 가지며 서로 다른 데이터를 담도록 처리한다.
따라서 전체 데이터를 조회할 경우가 생기면 join에 추가적인 연산이 필요하다.
이렇게만 본다면 결국 하나의 데이터베이스에서 작업하는 것이기 때문에 join이 필요한 수직적 파티셔닝은 단점이 더욱 커보인다. 어떤 경우에 좋은 것일까?
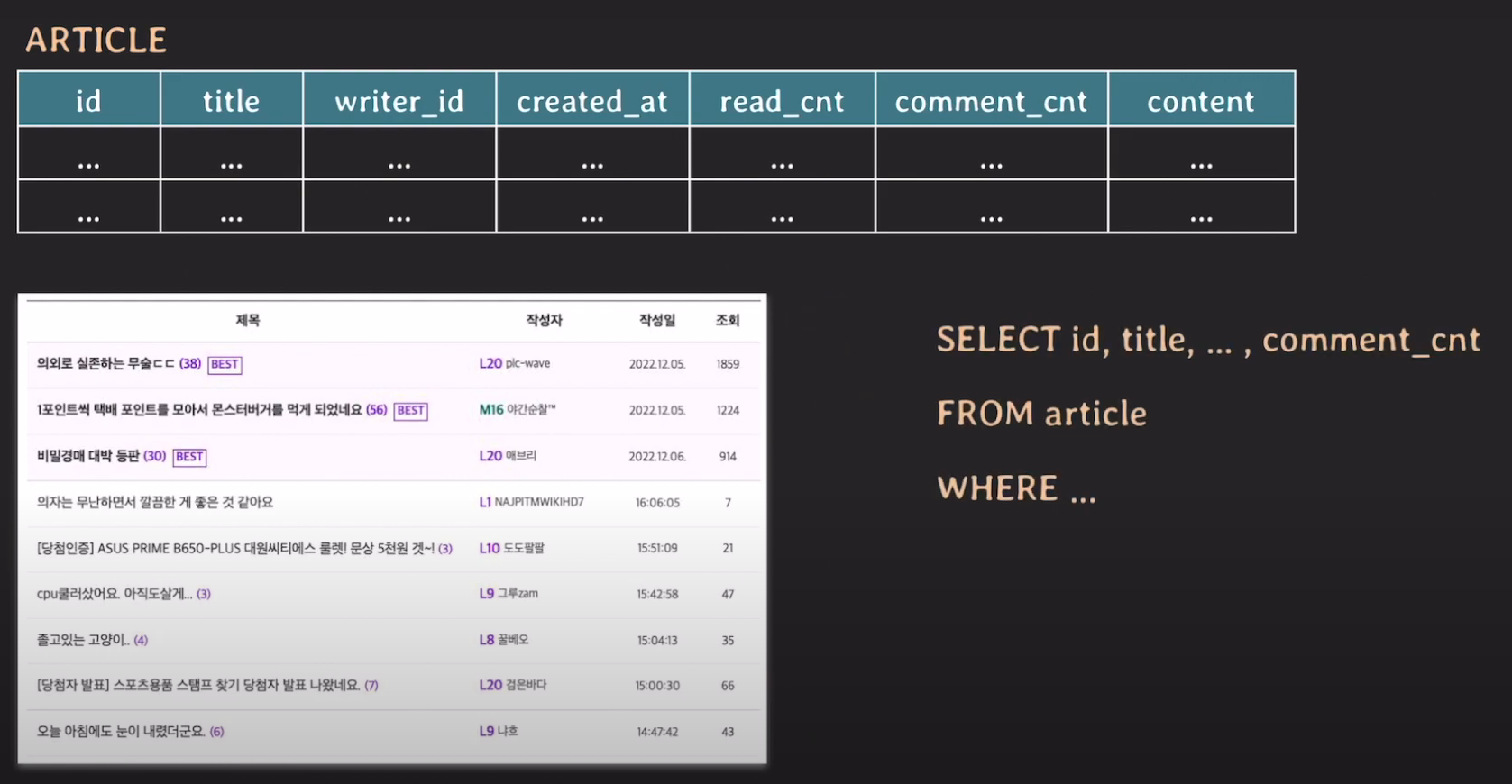
위와 같은 예시를 살펴보자. 일반적인 게시판 테이블이며 다양한 정보를 담고있다.
백엔드 관점에서 살펴보면 사용자가 게시판을 클릭했을 때, 오른쪽과 같은 쿼리문이 날라간다.
컴퓨터가 데이터를 가져와 처리하려면 결국 메모리에 데이터가 올라가야한다. 실제 데이터는 HDD나 SSD에 저장되고 우리는 그 중 필요한 부분을 페이지 단위로 디스크에서 메모리로 가져온다. (메모리와 디비 상호작용)
여기서 중요한점은, 처음부터 SELECT에 명시된 컬럼만을 메모리로 가져오는 것이 아니라는 점이다. DB는 해당 행의 모든 컬럼 데이터를 먼저 메모리에 로드한 후, SELECT 절에 맞춰 필터링한다.
여기서 문제가 생긴다. content 컬럼은 게시글의 본문으로, 일반적으로 긴 텍스트 데이터를 담고있다. 게시판 목록 화면에서는 content가 필요하지 않지만 하나의 테이블에 함께 있기 때문에 불필요한 content 데이터까지 메모리에 로드한다.
결과적으로 디스크 I/O가 증가해 성능에 영향을 미친다. 사용하지 않고 큰 데이터를 가지고 있는 content 컬럼 때문에 페이지 하나에 담을 수 있는 행의 개수가 줄어들고 같은 양의 게시글을 조회하더라도 더 많은 페이지를 읽어야 한다.

하지만 위와 같이 2개의 테이블로 분할한다면 content 데이터를 로드할 필요가 없기 때문에 한 페이지에 더 많은 행을 담을 수 있다.
결과적으로 디스크 I/O가 감소해 성능이 좋아진다.
이처럼 자주 조회되지 않는 큰 데이터를 분리해 불필요한 I/O를 줄이는 것이 수직적 파티셔닝의 핵심이다.
[ 수평적 파티셔닝 ]
수평적 파티셔닝은 데이터를 row 기준으로 나눠서 서로 다른 파티션에 저장하는 것이다.

A DB에서 1, 2, 3은 왼쪽, 4, 5는 오른쪽 파티션으로 나뉘어 저장된다.
이때 오해하면 안되는게 하나의 테이블에 대해서 여러개의 파티션으로 분할 하는 것이다.
따라서 하나의 DB에 존재하고 사용자는 기존 테이블에 대해서 SQL을 작성하면 된다.
파티션 테이블을 나누기 위해서는 CREATE를 할때 파티션을 지정해주는 방법이 있고 ALTER로 추후에 파티션을 추가하는 경우가 있다.
- CREATE 할 때 파티션을 지정하는 경우
CREATE TABLE orders (
id INT,
order_date DATE,
amount DECIMAL
) PARTITION BY RANGE (YEAR(order_date)) (
PARTITION p2023 VALUES LESS THAN (2024),
PARTITION p2024 VALUES LESS THAN (2025),
PARTITION p2025 VALUES LESS THAN (2026)
);
- ALTER를 통해 파티션을 추가하는 경우
ALTER TABLE orders
ADD PARTITION (
PARTITION p2026 VALUES LESS THAN (2027),
PARTITION p2027 VALUES LESS THAN (2028)
);파티션 또한 DROP을 통해 삭제할 수 있다.
[ 수평 파티션 분할 기준 ]
파티션을 나누기 위해서는 어떤 기준으로 나눌지 결정해야한다. 이 기준이 되는 것이 파티션 키이다.
파티션 키에 따라 데이터가 분할되어 저장되기 때문에 쿼리의 조건이 파티션키를 포함해야 효율적이다.
만약 파티션 키가 아닌 다른 컬럼을 조건으로 조회하는 쿼리가 많다면 오히려 분할된 파티션을 모두 조회해야 하기 때문에 성능이 저하될 수 있다.
-- 파티션 키(order_date)를 사용한 쿼리 → 빠름
SELECT * FROM orders WHERE order_date = '2024-01-15';
→ 하나의 파티션만 스캔
-- 파티션 키가 아닌 컬럼으로 쿼리 → 상대적으로 느림
SELECT * FROM orders WHERE customer_id = 100;
→ 모든 파티션을 스캔해야 함
1. 범위 기반 파티셔닝 (Range Partitioning)
연속적인 숫자나 날짜를 기준으로 나누는 방법이다.(created_at, order_date 등)
CREATE TABLE orders (
id INT,
order_date DATE,
amount DECIMAL
) PARTITION BY RANGE (YEAR(order_date)) (
PARTITION p2023 VALUES LESS THAN (2024),
PARTITION p2024 VALUES LESS THAN (2025),
PARTITION p2025 VALUES LESS THAN (2026)
);범위 기반 파티셔닝은 새로운 파티션을 추가하기 쉽다. 날짜를 기준으로 파티션을 생성했다면 단순히 새로운 날짜에 대한 파티션을 추가하면 된다.
하지만 날짜를 기준으로 한 경우 데이터의 분포가 불균등 할 수 있다. (2023년: 100만개, 2024년 10만개)
2. 해시 파티셔닝 (Hash Partitioning)
파티션키에 해시 함수를 적용한 값으로 나누는 방법이다.
CREATE TABLE users (
id INT,
name VARCHAR(100),
email VARCHAR(100)
) PARTITION BY HASH(id)
PARTITIONS 4;해시 파티셔닝은 범위 기반 파티셔닝보다 균등하게 파티션에 저장할 수 있다. 비슷한 양의 데이터가 저장되니까 파티션별로 부하가 고르게 분산된다.
하지만 파티션 추가 시 데이터 재분배가 필요하다. 해시 함수가 바뀌면서 기존 데이터의 위치가 변경되기 때문에 데이터를 재분배 해야하고 이는 시간과 리소스가 많이 소요되어 실제 서비스 운영에선 파티션 확장이 어렵다는 단점이 있다.
[ 파티션의 인덱스 ]
수직 파티셔닝의 경우에는 서로 다른 테이블로 구성되므로 기파티션을 사용하지 않을때와 똑같은 방식으로 인덱스를 구성할 것이다.
하지만 수평 파티셔닝의 경우에는?
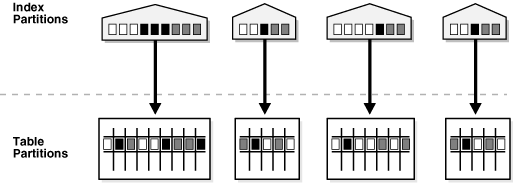
수평 파티셔닝의 경우 논리적으로는 하나의 테이블이지만 물리적으로는 여러 파티션에 분산 저장된다. 따라서 개발자는 하나의 테이블로 접근하지만 내부적으로는 각 파티션이 독립적인 테이블처럼 동작한다.
이때, 수평 파티션에는 로컬 인덱스, 글로벌 인덱스 두 가지 인덱스 방식이 있다.
[ 로컬 인덱스 ]
로컬 인덱스는 파티션별로 독립적인 인덱스를 관리하는 방식을 의미한다. 각 파티션이 자신만의 인덱스를 가지고 있기 때문에 파티션끼리 인덱스로 인한 영향을 주고받지 않는다. 따라서 특정 파티션을 삭제하더라도 해당 파티션의 인덱스만 함께 제거되고 다른 파티션의 인덱스는 영향을 받지 않는다.
로컬 인덱스는 파티션 키를 포함한 인덱스를 생성할 수도 있지만 다른 컬럼으로도 인덱스를 만들 수 있다.
예를 들어 order_date로 파티션을 나눈 테이블에서 customer_id로 인덱스를 생성하면, 각 파티션마다 customer_id 기준으로 인덱스가 추가로 생성된다.
보통의 경우 PK가 테이블마다 존재한다. 이때 테이블을 파티션으로 만들기 위해서는 MySQL 기준 PK에 파티션 키가 존재해야한다.
CREATE TABLE orders (
id INT PRIMARY KEY,
order_date DATE,
customer_id INT,
amount DECIMAL
);
-- 에러 발생
CREATE TABLE orders (
id INT PRIMARY KEY, -- 파티션 키(order_date) 미포함
order_date DATE,
customer_id INT,
amount DECIMAL
) PARTITION BY RANGE (YEAR(order_date)) (
PARTITION p2023 VALUES LESS THAN (2024),
PARTITION p2024 VALUES LESS THAN (2025),
PARTITION p2025 VALUES LESS THAN (2026)
);
-- 에러 발생 X
CREATE TABLE orders (
id INT,
order_date DATE,
customer_id INT,
amount DECIMAL,
PRIMARY KEY (id, order_date) -- 파티션 키인 order_date 포함
) PARTITION BY RANGE (YEAR(order_date)) (
PARTITION p2023 VALUES LESS THAN (2024),
PARTITION p2024 VALUES LESS THAN (2025),
PARTITION p2025 VALUES LESS THAN (2026)
);보통 auto_increment ID를 PK로 쓰기 때문에 파티션을 사용하기 위해서는 PK에 파티션 키도 포함시켜야한다 !!
[ 글로벌 인덱스 ]
글로벌 인덱스는 모든 파티션의 데이터를 하나의 통합 인덱스로 관리하는 방식이다. 데이터는 여러 파티션에 분산되어 저장되지만, 인덱스는 하나로 관리된다. 이 방식은 파티션 키 없이도 빠른 조회가 가능하다.

MySQL은 글로벌 인덱스를 지원하지 않는다. 따라서 Oracle의 예시를 보자.
CREATE TABLE SALES (
sales_no NUMBER,
sale_year NUMBER,
sale_month NUMBER,
sale_day NUMBER,
customer_name VARCHAR2(30),
birth_date DATE,
price NUMBER
)
PARTITION BY RANGE (sales_no) (
PARTITION SALES_P1 VALUES LESS THAN (3),
PARTITION SALES_P2 VALUES LESS THAN (5),
PARTITION SALES_P3 VALUES LESS THAN (MAXVALUE)
);
CREATE INDEX IDX_SALES_01 ON SALES (sales_no) GLOBAL;GLOBAL 키워드를 붙인다면 글로벌 인덱스로 생성된다.
CREATE TABLE SALES (
sales_no NUMBER,
sale_year NUMBER,
sale_month NUMBER,
sale_day NUMBER,
customer_name VARCHAR2(30),
birth_date DATE,
price NUMBER
)
PARTITION BY RANGE (sales_no) (
PARTITION SALES_P1 VALUES LESS THAN (3),
PARTITION SALES_P2 VALUES LESS THAN (5),
PARTITION SALES_P3 VALUES LESS THAN (MAXVALUE)
);
CREATE INDEX IDX_SALES_01 ON SALES (sales_no) LOCAL;
마찬가지로 LOCAL을 붙인다면 로컬 인덱스로 생성된다.
[ 로컬 인덱스를 많이 사용하는 이유 ]
로컬 인덱스와 글로벌 인덱스 중에서 로컬 인덱스를 많이 사용한다. 그 이유는 무엇일까?
로컬 인덱스가 관리하기 편하기 때문이다.
예를 들어 로그를 저장하는 테이블을 파티션 테이블로 만들었다고 해보자. 시간이 지나 로그의 보관 의무 기간이 끝나서 필요 없는 데이터를 제거해야한다. 이때 파티션 DROP을 수행할텐데 글로벌 인덱스로 구성되어 있다면 필요없는 테이블 파티션을 DROP한 뒤 인덱스가 깨지게된다.
ORA-01502: index or partition of such index is in usable state tips
ORA-01502: 인덱스 또는 인덱스의 분할 영역은 사용할 수 없는 상태입니다.
↑ 위와 같은 에러가 발생한다.
이렇게 인덱스가 깨져버리면 Invalid 상태가 되고 이 인덱스를 다시 사용하기 위해서는 인덱스 리빌딩 작업을 다시 해줘야 하는 등 번거로움이 있다. 하지만 로컬 인덱스로 구축했다면 문제가 발생하지 않는다. 로컬 인덱스는 각각의 파티션마다 하나씩 걸려 있기 때문에 파티션을 DROP 할 때 함께 제거되고 남아있는 파티션에는 전혀 지장이 없기 때문이다.
2. 샤딩
[ 샤딩 ]
수평 파티셔닝은 파티션 키를 통해서 하나의 테이블에서 서로 다른 파티션에 데이터를 저장했다. 샤딩은 샤드 키를 통해서 서로 다른 데이터베이스에 저장한다. 즉, 샤딩은 수평 파티셔닝과 비슷하지만 서로 다른 데이터베이스에 분산 저장하는것이 수평 파티셔닝과의 차이점이다.
샤딩 또한 범위 기반 샤딩, 해시 샤딩 등의 방법이 존재한다.
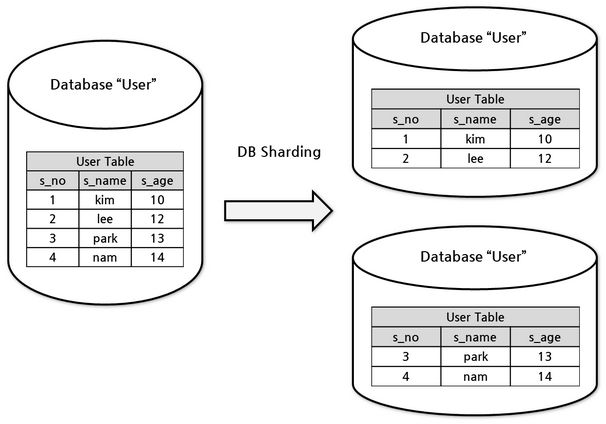
샤딩은 결국 서로 다른 데이터베이스에 접근을 해야하기에 서로 다른 DBMS를 다룬다.
따라서 샤딩을 배울 때 가장 궁금했던 점이 샤딩키를 통해서 서로 다른 데이터베이스에 어떻게 접근하는 가였다.
파티션의 경우 하나의 DBMS의 하나의 테이블에 대해 처리한 것이기 때문에 DBMS에 의해 가능했지만 샤딩은?
[ DB에서 샤딩 처리 ]
MongoDB, Casandra와 같은 NoSQL이 이를 지원한다. 또한 NoSQL 뿐만 아니라 RDBMS에서도 이러한 샤딩 기능을 이용할 수 있는 방법이 존재한다. 플랫폼 단위(미들웨어 추가)로 처리하는 것과 비슷한 개념이지만 샤딩로직이 DB 내부에 내장되어 있느냐(DB 내장형), 외부 미들웨어에 의해 처리되느냐(외부형)에 따라 구분할 수 있다.
ex) Spider, MySQL Fabric, PostgreSQL Citus 등
[ 애플리케이션 서버에서 처리 ]
DB에서 샤딩을 하게 된다면 특정 DBMS에 종속적이게 된다는 단점이 존재한다. 이에 애플리케이션 레벨에서 샤딩 로직을 구현하는 방법이 있다.
Spring의 경우 DataSource의 설정을 커스텀하여 사용하는 사례가 있다.
https://techblog.woowahan.com/2687/
이외에도 별도의 로직 구현 없이 비교적 편하게 사용할 수 있는 방법 또한 존재한다.
ex) Hibernate Shards, Shardingsphere-jdbc 등
[ 플랫폼 단위로 처리 ]
마지막으로 샤딩에 대한 책임을 별도로 분리할 수 있게 플랫폼 단위로 샤딩을 구현하는 방법이 있다. 샤딩 관리에 대한 부담을 줄이고 어플리케이션 로직에 집중할 수 있는 장점이 있다.
ex) Shardingsphere-proxy, Spock proxy, Gizzard, Cubrid shard 등
3. 애플리케이션 샤딩 실습
[ DataSource 커스터마이징 ]
첫번째는 라이브러리 없이 DataSource 커스터마이징으로 구성해보았다.
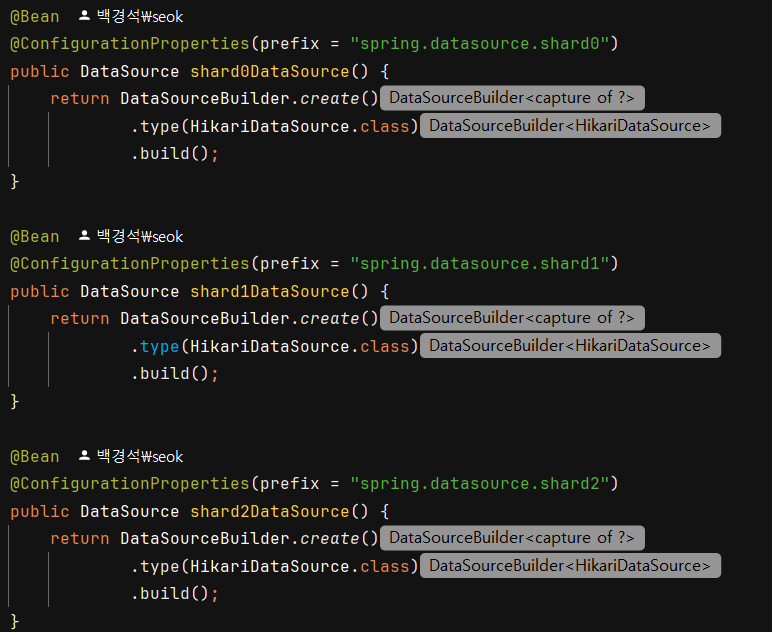
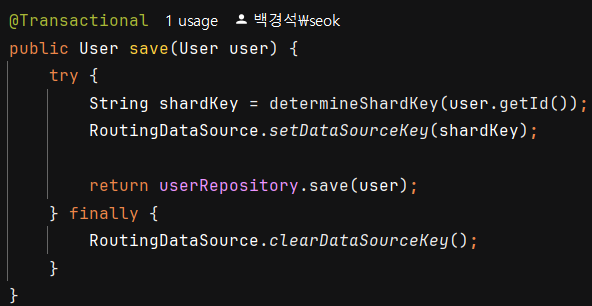
DataSource를 3개 만들어놓고 shardKey에 따라서 동적으로 어떤 DataSource에 저장할지를 처리했다.
이 방법을 쓰면 더 많은 설정을 관리해야하는 단점이 있다.
[ ShardingSphere ]
실습에 들어가기 전, 사용할 ShardingSphere가 뭔지에 대해서 알아보자.
ShardingSphere는 데이터베이스 샤딩, 데이터 복제, 트랜잭션 관리 등을 지원하는 Apache의 오픈소스로서 대규모 데이터베이스 환경에서 데이터의 분산 처리 및 관리의 복잡성을 줄이기 위해 설계되었다.
>앞서 언급한 솔루션 중 Shardingsphere-jdbc는 애플리케이션 레벨의 샤딩을

ShardingSphere-proxy는 플랫폼 기반의 샤딩을 지원한다.

ShardingSphere는 다음과 같이 분산된 DB, 테이블을 세개의 독립된 솔루션을 통해 하나의 Logic Table로서 접근 가능하도록 한다. 즉, 수평 파티셔닝을 DBMS가 처리해준 것 처럼 ShardingSphere가 처리해주는 것이다.
어떻게 이것을 가능하게 했는지 알아보자.

Sharding JDBC는 자바 어플리케이션 위에서 JDBC 형태로 동작한다.
Application의 비즈니스 로직에 따라 테이블 정보가 포함된 SQL을 실행하면 다음의 처리를 거쳐 DB에 접근한다.
- SQL Parse:
SQL문을 형태소 단위로 분해 - Query Optimize:
분해한 SQL문을 최적화 - SQL Route:
샤딩 룰, 샤딩 키등을 분석해 대상 DB, TABLE 선정 - SQL Rewrite:
선정 된 DB, TABLE에 기반하여 SQL문 재작성 - SQL Execute:
재작성된 SQL문 실행 - Result Merge:
각 SQL문 결과들을 Merge하여 하나의 테이블에 접근한 것 같은 통합된 ResultSet을 제공
즉, Spring Data Jpa가 내부적으로 JPQL → SQL로 변환시켜 JDBC로 DB에 전달하는 것처럼, 우리가 yml에 설정한 혹은 config 파일로 설정한 sharding rule에 따라서 Application layer에서 생성한 SQL을 적절한 SQL로 재생산해서 JDBC로 DB에 전달하는 것이다.
이런 자동화 기능을 제공하지만 주의해야 할 점도 존재한다.

해석해보면 ShardingSphere-JDBC는 자바 JDBC 레이어 위에 샤딩, 분산 트랜잭션, 읽기/쓰기 분리 등 추가적인 서비스를 제공하는 자바 프레임워크이다. 별도 서버없이 애플리케이션 단에서 바로 사용 가능하다.
ShardingSphere-JDBC를 사용할때 주의해야 할점은 애플리케이션의 메모리이다.
SQL을 Parse하는 과정을 거쳐야 하기 때문에 내부 캐시를 사용한다.그래서 애플리케이션에 서로 다른 SQL이 들어올수록 캐시가 커져 힙 메모리를 많이 사용할 수 있다. 아직 최적화가 완벽하지 않아서 JVM 힙 메모리(-Xmx) 설정을 늘려주는게 추천된다.
즉, ShardingSphere-JDBC는 애플리케이션 레벨에서 SQL을 샤딩/분산 처리하도록 재작성해 DBMS가 파티셔닝을 처리하는 것과 유사한 역할을 수행하지만, 애플리케이션에서 수행되기 때문에 JVM 힙 메모리를 많이 사용할 수 있다는 단점이 있다. 따라서 JVM 힙 메모리를 충분히 늘려주는게 권장된다. 라고 해석 할 수 있다.
[ ShardingSphere - JDBC ]
깃허브 링크: https://github.com/Hellin22/hellin22-test-repo/tree/main/sharding-with-ShardingSphere
0. Docker-Compose
services:
mysql1:
image: mysql:8.0
container_name: mysql1
restart: always
environment:
MYSQL_ROOT_PASSWORD: root
MYSQL_DATABASE: db
MYSQL_USER: user
MYSQL_PASSWORD: 1234
ports:
- "3307:3306"
volumes:
- mysql1-data:/var/lib/mysql
- ./mysql1-init.sql:/docker-entrypoint-initdb.d/init.sql
command: --default-authentication-plugin=mysql_native_password
mysql2:
image: mysql:8.0
container_name: mysql2
restart: always
environment:
MYSQL_ROOT_PASSWORD: root
MYSQL_DATABASE: db
MYSQL_USER: user
MYSQL_PASSWORD: 1234
ports:
- "3308:3306"
volumes:
- mysql2-data:/var/lib/mysql
- ./mysql2-init.sql:/docker-entrypoint-initdb.d/init.sql
command: --default-authentication-plugin=mysql_native_password
mysql3:
image: mysql:8.0
container_name: mysql3
restart: always
environment:
MYSQL_ROOT_PASSWORD: root
MYSQL_DATABASE: db
MYSQL_USER: user
MYSQL_PASSWORD: 1234
ports:
- "3309:3306"
volumes:
- mysql3-data:/var/lib/mysql
- ./mysql3-init.sql:/docker-entrypoint-initdb.d/init.sql
command: --default-authentication-plugin=mysql_native_password
networks:
default:
name: sharding-net
volumes:
mysql1-data:
mysql2-data:
mysql3-data:
1. 종속성
implementation 'org.apache.shardingsphere:shardingsphere-jdbc:5.5.2인터넷에 존재하는 많은 예시가 현재 안되는 경우가 많아서 고생했다. 특히 shardingsphere-jdbc의 경우 설정 yml을 로드해서 클래스를 생성하는데, 관련 종속성이 맞지 않아 실패하는 경우가 많았다.
꼭 repository에서 버전을 제대로 확인하고 추가하자.
https://mvnrepository.com/artifact/org.apache.shardingsphere/shardingsphere-jdbc
추가로 Guava 의존성을 추가했다. Guava는 Cache나 LoadingCache 같은 메모리 캐시 기능을 제공하고 shardingsphere-jdbc가 Guava의 캐시 기능을 사용한다.
예전에는 Maven 의존성 안에 Guava가 포함돼 있어서 별도로 추가할 필요가 없었는데 현재 프로젝트 환경에서는 shardingsphere-jdbc만 추가하면 Guava가 자동으로 포함되지 않아서 처리할 수 없다는 에러가 발생했다. 따라서 직접 Guava 읜존성을 추가했다.
implementation 'com.google.guava:guava:32.1.3-jre'
2. application.yml
ShardingSphere를 통해 데이터베이스와 통신하기 때문에 기존의 datasource 설정은 필요없다.
spring:
datasource:
driver-class-name: org.apache.shardingsphere.driver.ShardingSphereDriver
url: jdbc:shardingsphere:classpath:sharding.yml
jpa:
properties:
hibernate:
dialect: org.hibernate.dialect.MySQL8Dialect
hibernate:
ddl-auto: update
3. sharding.yml
dataSources:
ds0:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://localhost:3307/db?useSSL=false&allowPublicKeyRetrieval=true&serverTimezone=UTC&characterEncoding=UTF-8
username: user
password: 1234
ds1:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://localhost:3308/db?useSSL=false&allowPublicKeyRetrieval=true&serverTimezone=UTC&characterEncoding=UTF-8
username: user
password: 1234
ds2:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://localhost:3309/db?useSSL=false&allowPublicKeyRetrieval=true&serverTimezone=UTC&characterEncoding=UTF-8
username: user
password: 1234
rules:
- !SHARDING
tables: # 샤딩할 테이블
user:
actualDataNodes: ds${0..2}.user
keyGenerateStrategy:
column: user_id
keyGeneratorName: snowflake
defaultDatabaseStrategy: # 데이터베이스 샤딩 전략
standard:
shardingColumn: user_id
shardingAlgorithmName: database_inline
defaultTableStrategy:
none:
shardingAlgorithms: # 샤딩 알고리즘
database_inline:
type: INLINE
props:
algorithm-expression: ds${user_id % 3}
keyGenerators: # 키 생성기
snowflake:
type: SNOWFLAKE
props:
worker-id: 123
props:
sql-show: true위의 shardingsphere 공식 사이트에서 yml 설정 방법을 보고 설정하자.
4. Test
[ shard key로 SELECT ]


Logic SQL(실제로 보낸 SQL)과 Actual SQL(ShardingSphere-JDBC가 Logic SQL을 해석하고 재생성하여 실제로 JDBC로 보내는 SQL)이 분리되어 처리되는 걸 확인할 수 있다.
샤드 키 조건에 따라 SQL이 ds0라는 특정 샤드로 라우팅 되어서 데이터를 조회한다.
즉, 샤딩이 정상적으로 적용된 것을 확인할 수 있다.
[ non shard key로 SELECT ]


마찬가지로 Logic SQL이 Actual SQL로 재생성 되어서 처리된다.
하지만 샤드 키 조건이 없기 때문에, 어떤 데이터베이스에 데이터가 있는지를 알 수 없어 모든 샤드(ds0, ds1, ds2)를 다 조회한다.
이런 경우 불필요한 I/O가 증가할 수 있으므로 샤딩을 적용할 때에는 어떤 컬럼을 샤드 키로 지정할지가 중요하다.
5. ShardingSphere-JDBC 느낀점
직접 DataSource를 커스텀하여 샤드 키를 추출하고 동적으로 샤드를 결정하는 방법과, ShardingSphere-JDBC를 활용하여 자동 라우팅으로 처리하는 방법 두 가지를 해보았다.
ShardingSphere를 사용할 경우, 샤드 키 조건이 없더라도 자동으로 라우팅 처리를 해주는 점이 편리했다.
반면, 커스텀 방식에서는 샤드 키가 없는 요청이 들어오면 모든 데이터베이스를 조회해야 하고, 이를 직접 구현하고 관리해야 한다. 이러한 과정은 개발의 복잡도를 높이고, 연결 처리와 에러 대응에 더 많은 시간이 소요될 수 있다.
따라서 샤딩 로직을 안정적이고 효율적으로 구현하려면, 가능하다면 ShardingSphere-JDBC 같은 프레임워크를 활용하는 것이 생산성과 안정성 측면에서 좋을 것 같다고 느꼈다.
출처
1. https://spiderwebcoding.tistory.com/14
2. https://coding-factory.tistory.com/841
3. https://youtu.be/P7LqaEO-nGU?si=GWoEYPu9VEDRD5dq
4. https://nadermedhatthoughts.medium.com/understand-database-sharding-the-good-and-ugly-868aa1cbc94c
5. https://velog.io/@nickygod/RDB%EC%9D%98-%EC%83%A4%EB%94%A9-%EA%B8%B0%EB%B2%95-Shardingsphere
'일기' 카테고리의 다른 글
| [개발일기] JWT와 Session에 대한 생각 (2) | 2025.10.15 |
|---|---|
| [개발일기] MongoDB Sharding with mongos, config (0) | 2025.10.08 |
| [개발일기] - 인덱스에 대해서 자세히 알아보기 (0) | 2025.10.01 |
| [개발일기] 09.19 - 데이터베이스란 무엇인가? (0) | 2025.09.19 |
| [개발일기] 09.17 - JVM의 GC는 어떻게 동작할까? (0) | 2025.09.17 |